monotone.
Store and manage events and time-series data locally or on top of S3, with
seamless, low-latency access directly within your application.



Slack
GitHub
Storage for Sequential data
We designed a modern embeddable key-value storage from the ground
up precisely for sequential workloads, such as
append write
and
range scans
.
Sequential workloads are typical of the wide variety of modern use cases: IoT, events, time series, crypto, blockchain, finance, monitoring, logs collection, and Kafka-style processing.
Using Monotone, you can create high-performance serverless solutions for storage and processing data directly within your application.
Sequential workloads are typical of the wide variety of modern use cases: IoT, events, time series, crypto, blockchain, finance, monitoring, logs collection, and Kafka-style processing.
Using Monotone, you can create high-performance serverless solutions for storage and processing data directly within your application.
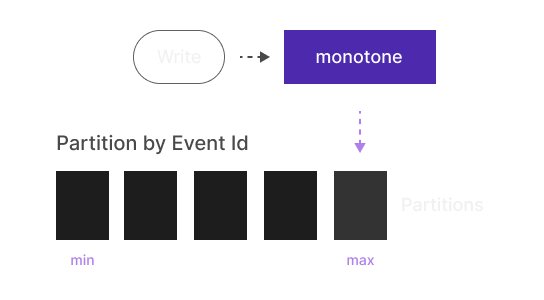
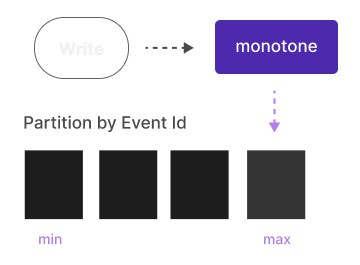
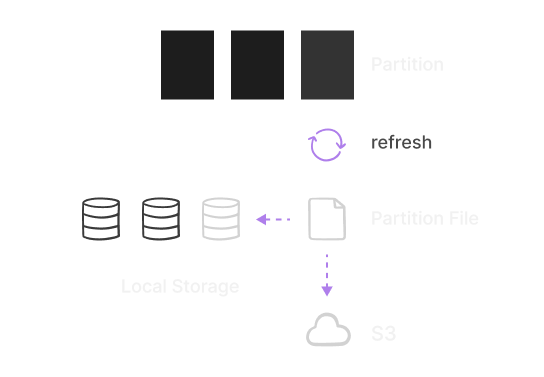
Automatic Range Partitioning
Automatically partition data by range or time intervals (min/max).
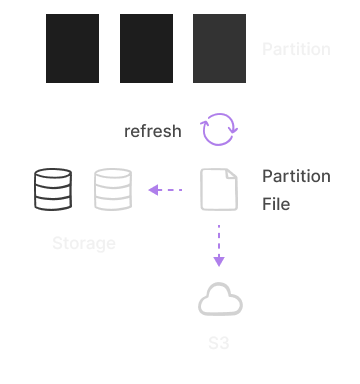
Transparently create partitions on write. Automatically or manually
refresh partitions on disk or cloud after being updated. Automatically
exclude unrelated partitions during reading.
Transparent Compression
Compress and recompress partitions automatically on refresh (or
partition move). Allow different compression types and compression
level settings. Everything is done transparently without blocking
readers and writers.
Transparent Encryption
Encrypt and decrypt partitions automatically on refresh, partition
move, or read. Compatible with compression and done transparently.

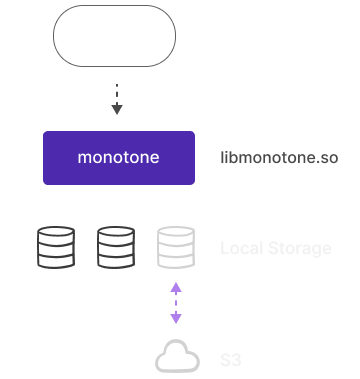
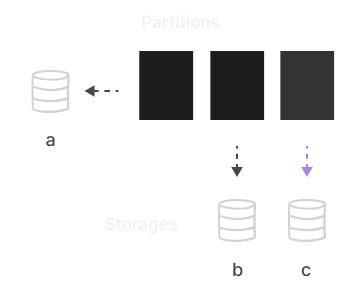
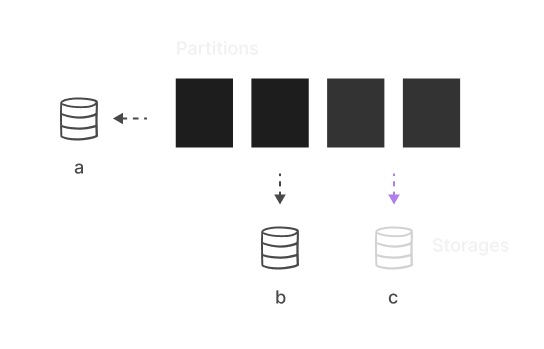
Multiple Storages
Create logical storage to store data on different storage devices. Set
different storage settings, such as compression, encryption,
associated cloud, etc. Create or drop storage online. Extend disk
space by adding new storage without downtime.
Manually or automatically move partitions between storages. Compaction on the move can be automatically done to change settings.
Manually or automatically move partitions between storages. Compaction on the move can be automatically done to change settings.
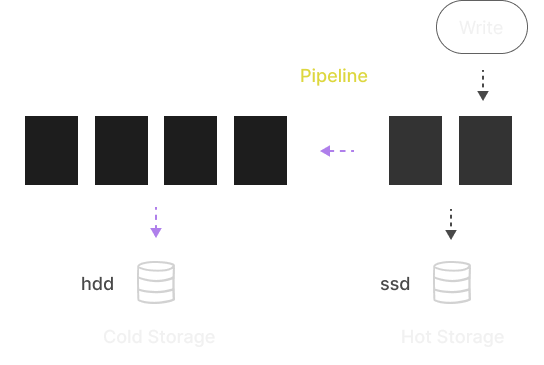
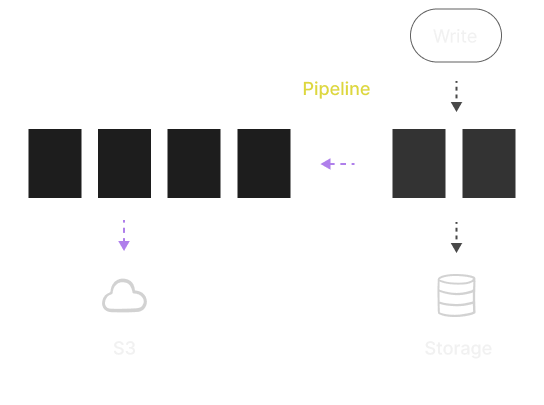
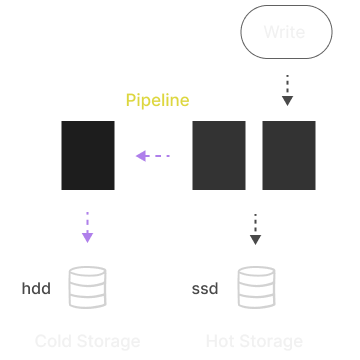
Data Tiering
Create data policies involving several storages to separate hot and
cold data. Define a pipeline to specify where partitions are created
and when they need to be moved or dropped. This can be done
automatically or manually.
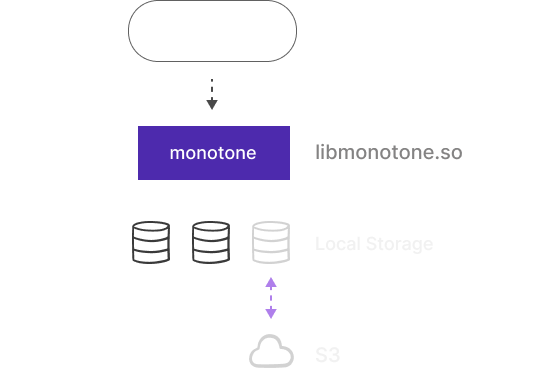
Cloud Storage
Associate storage with the cloud for extensive and cheaper storage.
Transparently access partitions on the cloud. Automate the lifecycle
of partitions for the cloud using a Pipeline.
You can automatically or manually handle updates by reuploading partitions to the cloud, downloading or uploading partitions, moving partitions between local storage and the cloud, or moving partitions between different cloud services.
You can automatically or manually handle updates by reuploading partitions to the cloud, downloading or uploading partitions, moving partitions between local storage and the cloud, or moving partitions between different cloud services.